
В нашій системі VDoc для зберігання та поширення файлів та документів виникла потреба розпізнавати звукові дорожки українською мовою з відео та переводити їх в текст. Спробував знайти рішення. ChatGPT довго думав над файлом і врешті, нічого не декодував. Інші штучні інтелекти, взагалі сказали, що не готові до такої задачі. Рішення від Гугл написало, що файл занадто велик для розпізнавання, прийшлось, кодити рішення самому на Python.
1. Встановлюємо vosk:
pip install vosk
2. Встановлюємо DeepMultilingualPunctuation (для додавання пунктуації):
pip install deepmultilingualpunctuation
3. Wave (вбудована бібліотека Python, але переконайтеся, що вона доступна)
# Якщо ви користуєтеся Windows і отримуєте помилки, можливо, потрібно встановити:
pip install wave
4. Модель Vosk для української мови
На сайті https://alphacephei.com/vosk/models ви можете закачати різні моделі для розпізнавання голосу.
Оберіть модель vosk-model-uk-v3-lgraph.
Розпакуйте її у директорію проекту або вкажіть правильний шлях до неї у коді:
model = Model("path/to/vosk-model-uk-v3-lgraph")
5. FFmpeg
Що це? FFmpeg — це програма для обробки мультимедіа.
Як встановити?
На Linux:
sudo apt update
sudo apt install ffmpeg
На macOS:
brew install ffmpeg
На Windows:
Завантажте та встановіть з офіційного сайту FFmpeg .
Додайте FFmpeg до змінної середовища PATH.
Перевірте, чи працює FFmpeg:
ffmpeg -version
6. Файли для обробки
video.mp4 : Вхідне відео, з якого буде витягнуто аудіо.output_audio.wav : Міжпроміжний WAV-файл без фільтрації шуму.clean_audio.wav : Аудіо після застосування фільтрації шуму.decoded_text.txt : Файл, де буде збережено розпізнаний текст.Програмний код decode_simple.py:
import subprocess
from vosk import Model, KaldiRecognizer
import wave
import json
from deepmultilingualpunctuation import PunctuationModel
video_path = "video.mp4"
audio_path = "output_audio.wav"
clean_audio_path = "clean_audio.wav"
text_output_path = "decoded_text.txt"
extract_audio_cmd = [
"ffmpeg", "-i", video_path,
"-acodec", "pcm_s16le", "-ar", "16000", "-ac", "1",
audio_path, "-y"
]
subprocess.run(extract_audio_cmd, stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL)
print(f"Аудіо витягнуто: {audio_path}")
subprocess.run(["ffmpeg", "-i", audio_path, "-af", "afftdn", clean_audio_path, "-y"])
print(f"Шум відфільтровано: {clean_audio_path}")
model = Model("vosk-model-uk-v3-lgraph")
rec = KaldiRecognizer(model, 16000)
punctuation_model = PunctuationModel()
batch_size = 3
text_batch = []
with wave.open(clean_audio_path, "rb") as wf, open(text_output_path, "w", encoding="utf-8") as text_file:
print("
Розпізнавання тексту...
")
while True:
data = wf.readframes(4000)
if len(data) == 0:
break
if rec.AcceptWaveform(data):
raw_text = json.loads(rec.Result())["text"]
if raw_text.strip():
text_batch.append(raw_text)
if len(text_batch) >= batch_size:
combined_text = " ".join(text_batch)
formatted_text = punctuation_model.restore_punctuation(combined_text)
print(formatted_text)
text_file.write(formatted_text + "
")
text_batch = []
if text_batch:
combined_text = " ".join(text_batch)
formatted_text = punctuation_model.restore_punctuation(combined_text)
print(formatted_text)
text_file.write(formatted_text + "
")
print(f"
Розпізнаний текст збережено у {text_output_path}")
Виконуємо:
python3 decode_simple.py
Результат роботи програми:
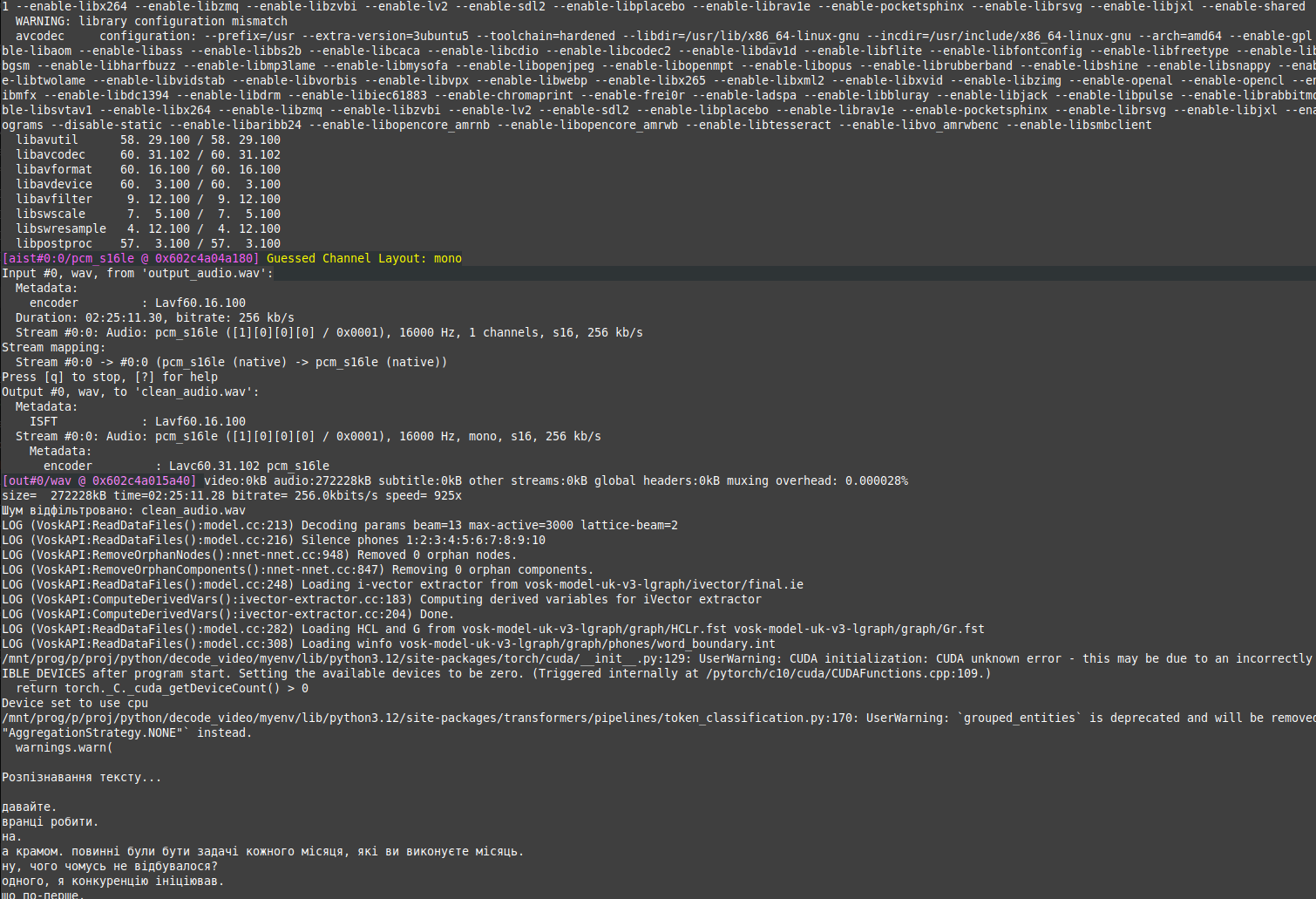
Текст декодуэться, але дуже коряво. Вставляє слова, які не говорили, спотворюється сказане доволі сильно. Тим не менш, частину слів декодує.
Похідний код decode_silero.py:
import subprocess
from vosk import Model, KaldiRecognizer
import wave
import json
import torch
import re
video_path = "video.mp4"
audio_path = "output_audio.wav"
clean_audio_path = "clean_audio.wav"
text_output_path = "decoded_text.txt"
# Витягуємо аудіо з відео
extract_audio_cmd = [
"ffmpeg", "-i", video_path,
"-acodec", "pcm_s16le", "-ar", "16000", "-ac", "1",
audio_path, "-y"
]
subprocess.run(extract_audio_cmd, stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL)
print(f"Аудіо витягнуто: {audio_path}")
# Видаляємо шум
subprocess.run(["ffmpeg", "-i", audio_path, "-af", "afftdn", clean_audio_path, "-y"])
print(f"Шум відфільтровано: {clean_audio_path}")
# Завантажуємо модель Vosk
model = Model("vosk-model-uk-v3-lgraph")
rec = KaldiRecognizer(model, 16000)
# Завантажуємо модель Silero для пунктуації
silero_model = torch.hub.load("snakers4/silero-models", "silero_te")
apply_te = silero_model[0]
# Функція очищення тексту
def clean_text(raw_text):
cleaned_text = re.sub(r"[^а-яА-Яa-zA-Z0-9s]", "", raw_text)
return cleaned_text.strip()
# Функція додавання пунктуації
def add_punctuation(text):
if not text.strip():
return ""
try:
return apply_te.enhance_text(text)
except Exception as e:
print(f"Помилка при додаванні пунктуації: {e}")
return text
batch_size = 3
text_batch = []
with wave.open(clean_audio_path, "rb") as wf, open(text_output_path, "w", encoding="utf-8") as text_file:
print("
Розпізнавання тексту...
")
while True:
data = wf.readframes(4000)
if len(data) == 0:
break
if rec.AcceptWaveform(data):
raw_text = json.loads(rec.Result())["text"]
if raw_text.strip():
cleaned_text = clean_text(raw_text)
if cleaned_text:
text_batch.append(cleaned_text)
if len(text_batch) >= batch_size:
combined_text = " ".join(text_batch)
formatted_text = add_punctuation(combined_text)
print(formatted_text)
text_file.write(formatted_text + "
")
text_batch = []
if text_batch:
combined_text = " ".join(text_batch)
formatted_text = add_punctuation(combined_text)
print(formatted_text)
text_file.write(formatted_text + "
")
print(f"
Розпізнаний текст збережено у {text_output_path}")
Виконувати:
python3 decode_silero.py
Результат виконання програми:
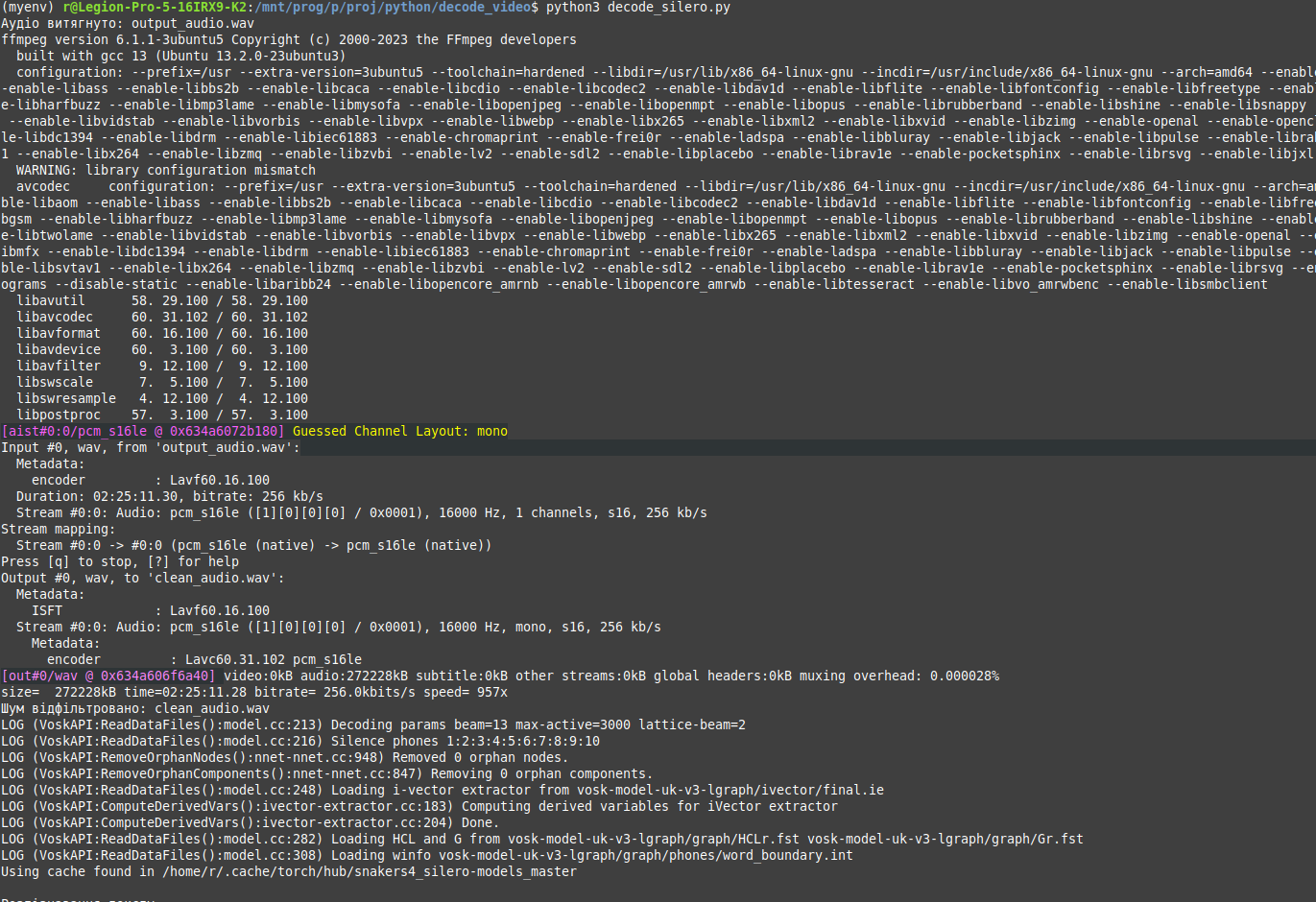
Автор: Рудюк С.А.
 Українська
Українська  English
English Poland
Poland