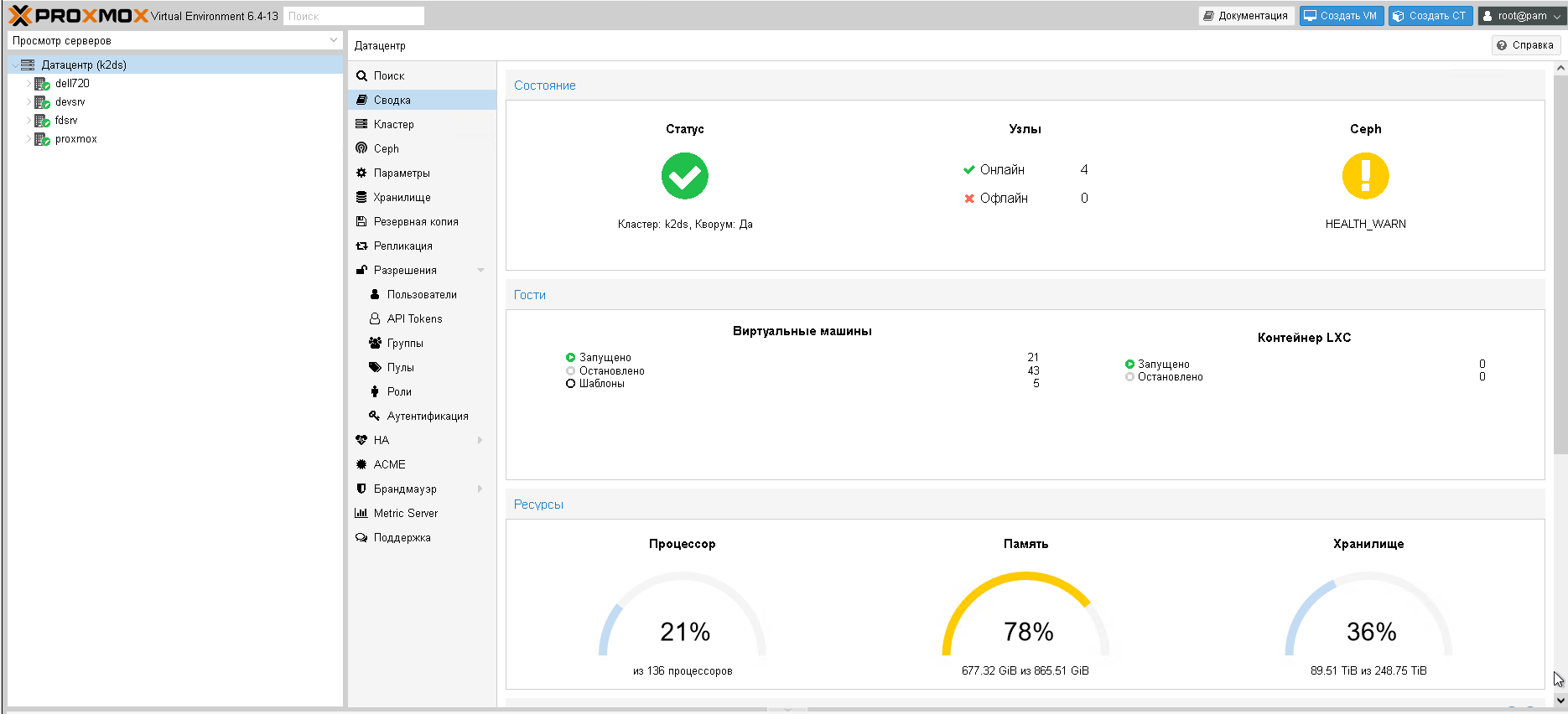
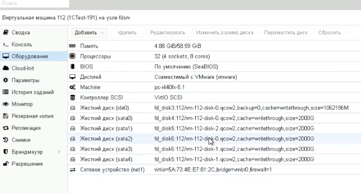
Один із напрямків нашого бізнесу – це надання хостингу для систем автоматизації. Ми маємо власні кластери серверів. Один з кластерів складається з чотирьох потужних серверів, які встановлені на стороні дата-центру. На цьому кластері працює багато віртуальних машин, які ділять між собою ресурси.
Параметри цього кластера:
-136 процесорів;
- 865 гігабайтів оперативної пам’яті;
- 248 терабайтів дискового простору.
Якось наприкінці робочого тижня ми помітили, що один з фізичних серверів поводиться дивно – не відповідає адмінці кластерів. При цьому самі віртуальні сервери працювали.
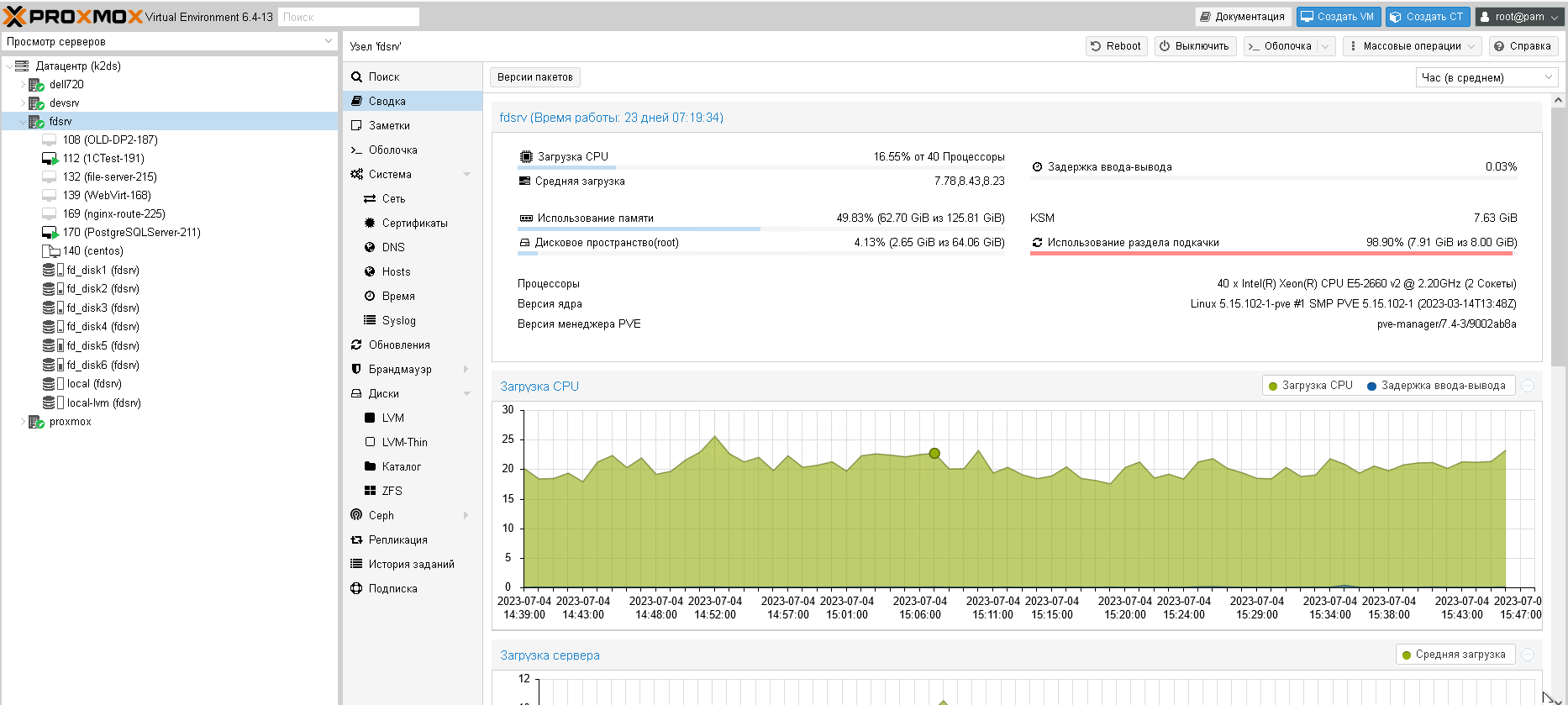
Цей сервер мав істотну потужність: 40 процесорів, оперативна пам‘ять – 128 гігабайтів, дисковий простір 70 терабайтів. Його не перезавантажували 197 днів і ми розуміли, що у випадку, коли сервери такий тривалий час працюють без перезавантаження, то існує ризик того, що сервер не запуститься.
Тому ми завчасно попередили наших клієнтів, що сервер буде перезавантажений у п’ятницю тоді, коли всі працівники та регламенти завершать роботу.
Ми планували перезавантажити сервер вночі; дали команду перезавантаження о 3 годині ночі, але сервер так і не перезавантажився. Тому адміністратор пішов відпочивати.
О 7 годині ранку адміністратор перевірив доступність сервісів й побачив, що сервер пішов в перезавантаження, але не запустився.
На той момент була невідома причина, по якій сервер не перезавантажився. Перевірка інших серверів показала, що інші сервери працюють, тому очевидно проблема була з цим конкретним сервером.
Хоча інші сервери працювали, однак частина сервісів була недоступна через те, що на цьому фізичному сервері був проксуючий вебсервер та кластер облікової системи одного з клієнтів.
Адміністратор поїхав в дата-центр, щоб подивитись, яка саме проблема виникла на сервері.
Але на місці виявилося, що в суботу чергових техніків дата-центру не було на місці; крім того, в них не було ні монітора, ні KVM, ні навіть клавіатури. Тому довелося їхати за монітором та клавіатурою в офіс. Таким чином, було втрачено годину часу на розв‘язання проблеми з підключенням до сервера (ось, до речі, мінус чужих дата-центрів, у своїх такі проблеми не виникають).
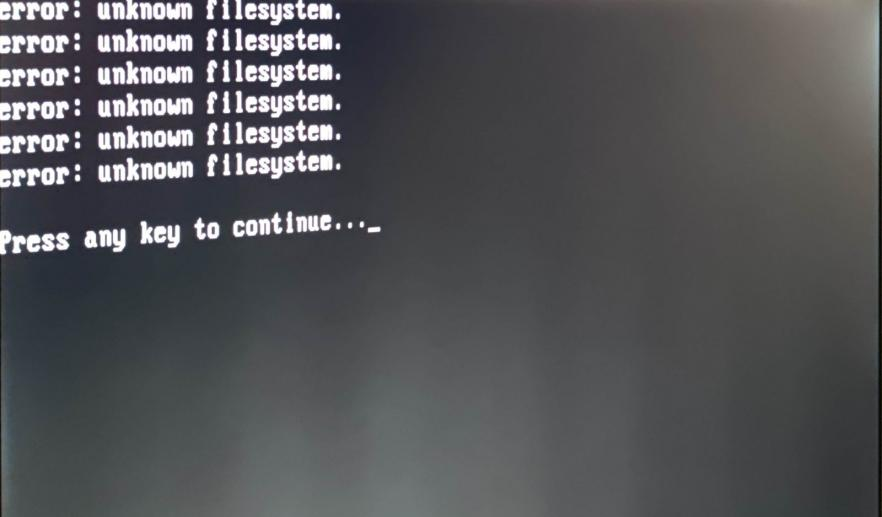
Коли було під‘єднано монітор, ми побачили наступне:
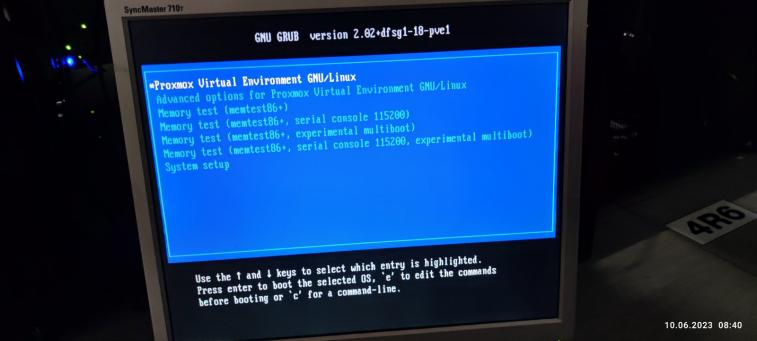
Після цього повідомлення система поверталась до меню запуску. Будь-які дії з GRAB не дали ніякого результату. Тому ми вимушені були взяти сервер на діагностику в офіс.
Приїхавши в офіс, ми під‘єднали сервер до стенда, завантажились с завантажувального диска та побачили, що диски працюють:
Щойно стало зрозуміло, що розв‘язання проблеми затягнеться, ми попередили про це клієнта. Пізніше став зрозумілий розмір каскадної аварії. Те, що цей сервер був у неробочому стані, мало наступні наслідки:
- Не працювали сайти, бо не працював проксуючий вебсервер, який відповідав за https (хоча самі сервери та бази даних працювали).
- Не працювала облікова система клієнта.
- Раптово перестала надавати права управління віртуальними машинами адмінка ProxMox (як виявилося пізніше, саме цей сервер був контролером віртуальних машин). Це призводило до того, що не можна було перекинути віртуальні машини з одного сервера на інші й запустити там.
Хоча розмір каскадної аварії був досить великий, однак проблеми через це були мінімальними – тому, що сама аварія виникла у вихідні (ми вдало вибрали час для перезавантаження сервера).
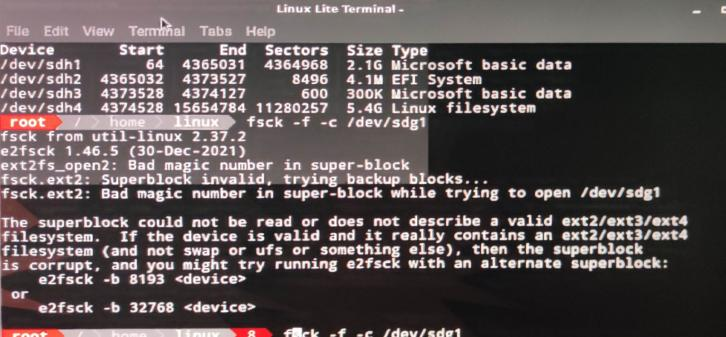
Досліджуючи сервер, ми дійшли висновку, що причиною виходу з ладу сервера було те, що розділ LVM на завантажувальному диску вийшов з ладу.
Виявилось, LVM відновлюється складніше, ніж EXT4, FAT, NTFS. Щоб його відновити, було потрібно, щоб прочитувались суперблоки. При намаганні вказати інші суперблоки нам видавало помилку про те, що диск не читається і потрібно вказати іншу адресу суперблока.
На відміну від звичайних систем (EXT4, FAT, NTFS тощо), які можна поновлювати, структура LVM диску така, що якщо він не завантажується із суперблоків, то вже не підлягає відновленню.
Тобто, у нас склалася така ситуація, що хоча інформація була на дисках, ми не могли відновити віртуальні машини.
Всі інші диски були робочі, ми до них під‘єдналися, що було добре, адже вся інформація збереглася, диски читалися, показувалися файли, інформація копіювалася.
Першою ідеєю було перенести всю інформацію на інші сервери. Але те, що адмінка віртуальних машин не давала управляти ними, створювало проблему запуску переписаної віртуальної машини. Крім того, обсяг, який потрібно було перенести, склав 15 терабайтів. Такий обсяг може копіюватись між серверами декілька діб.
Був інший варіант – перевстановити систему й перезапустити сервер, як ми врешті-решт й зробили. Але тут також виникала певна проблема: сервер облікової системи клієнта мав шість вінчестерів, які необхідно було увімкнути у правильній послідовності й не помилитися, бо в разі помилки був високий ризик, що система не завантажиться.
Оскільки на диску, який вийшов з ладу, зберігалась інформація про віртуальні машини, ми спочатку вирішили вирахувати диски вручну. Тобто, пройшлись по всім файлам віртуальних дисків, подивилися дати й таким чином вирахували ті віртуальні машини, які були запущені перед аварією. Наприклад, якщо ми бачили, що файл 2022 року, то розуміли: ця віртуальна машина була вимкнена і не змінювалася. Нам були потрібні лише файли 2023 року, приблизно тих дат, коли система вийшла з ладу. Таким чином, ми пройшлися по всім шести дисках й вирахували потрібні файли.
Хоча диски були вирахувані, але не було повної впевненості в тому, що ми правильно вирахували послідовність їх включення. А це могло призвести до ризиків незапуску операційної системи в віртуальній машині, а також до ризиків затягування розв‘язання проблеми.
Для відновлення управління віртуальними машинами потрібно було перезібрати кластер ProxMox. Це було ризиковано робити на реальному кластері. На щастя, у нас в офісі залишилася частина апаратури, яка була виведена з використання на час блекауту.
Ми відновили апаратуру в серверній офісу, включили її та відновили кластер.
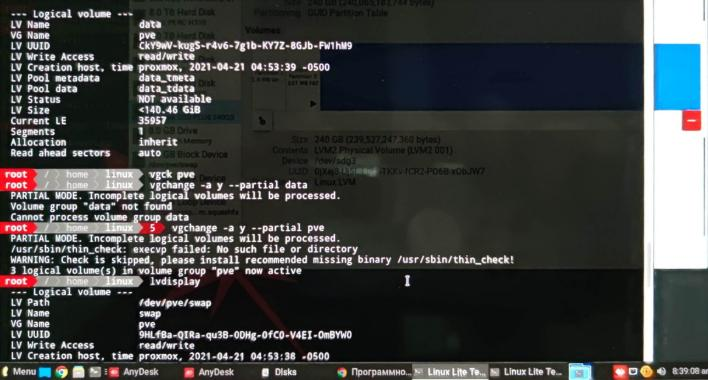
Аналізуючи кластер й розмірковуючи, як його відновити, адміністратор раптом побачив, що параметри про віртуальні машини автоматично дублюються на всіх серверах кластера. Саме це дозволило відновити всі віртуальні машини, які були на сервері, що вийшов з ладу, – простим копіюванням конфігураційних файлів з іншого серверу.
Каскадні аварії в IT – це найскладніший вид аварій. Подібну до нашої, яку ми спромоглися ліквідувати за добу, інші спеціалісти з меншим досвідом могли б вирішувати впродовж двох-трьох тижнів й ризикували навіть втратити інформацію. Це було б критично, бо весь цей час не працювали б склади клієнтів.
Як саме нам вдалося всього за двадцять чотири години впоратися з такою складною аварією:
- Висока кваліфікація та досвід адміністратора.
- Довіра клієнтів до нашої кваліфікації.
- Вчасно визначені ризики та перенесення ризику виникнення аварії на зручний для цього час.
- Ми завчасно попередили клієнтів, що дало їм змогу планувати свої ризики.
- Ретельна аналітика та багаторічний досвід. Спеціаліст з меншим досвідом міг наробити багато помилок. Наприклад, спробувати скопіювати віртуальні машини розміром 15 терабайтів і не врахувати, що на це знадобиться декілька днів, причому, без жодної гарантії, що все скопіюється якісно. Ми ж на це не пішли, а скопіювали маленьку машину розміром всього 30 гігабайтів, вже в той момент, коли кластер було відновлено й було розуміння, що буде можливим її запустити. Адже копіювати віртуальну машину без управління кластером не мало сенсу, бо потім не зможеш її запустити. Тому ми спочатку відновили кластер, потім, розуміючи, що його відновлено, скопіювали цю віртуальну машину та запустили й перевстановили операційну систему на цьому сервері.
Завдяки грамотному підходу ми не втратили інформацію та все чудово запрацювало.
 Українська
Українська  English
English Poland
Poland